Speech AI/음성 합성
[음성합성] Tacotron2 Model
1code
2021. 12. 6. 20:00
728x90
Tacotron2
2018년 Google에서 "Tacotron2"라는 TTS(Text-to-Speech) 모델을 발표하였다.
Tacotron2는 한 문장을 다른 문장으로 변환하는 구조인 "Seq2Seq(Sequence-to-Sequence)"를 기반으로한 모델이다.
Tacotron2는 아래 그림과 같은 구조로 이루어져 있고, 크게 인코더, 디코더, 어텐션으로 구성되어있다.
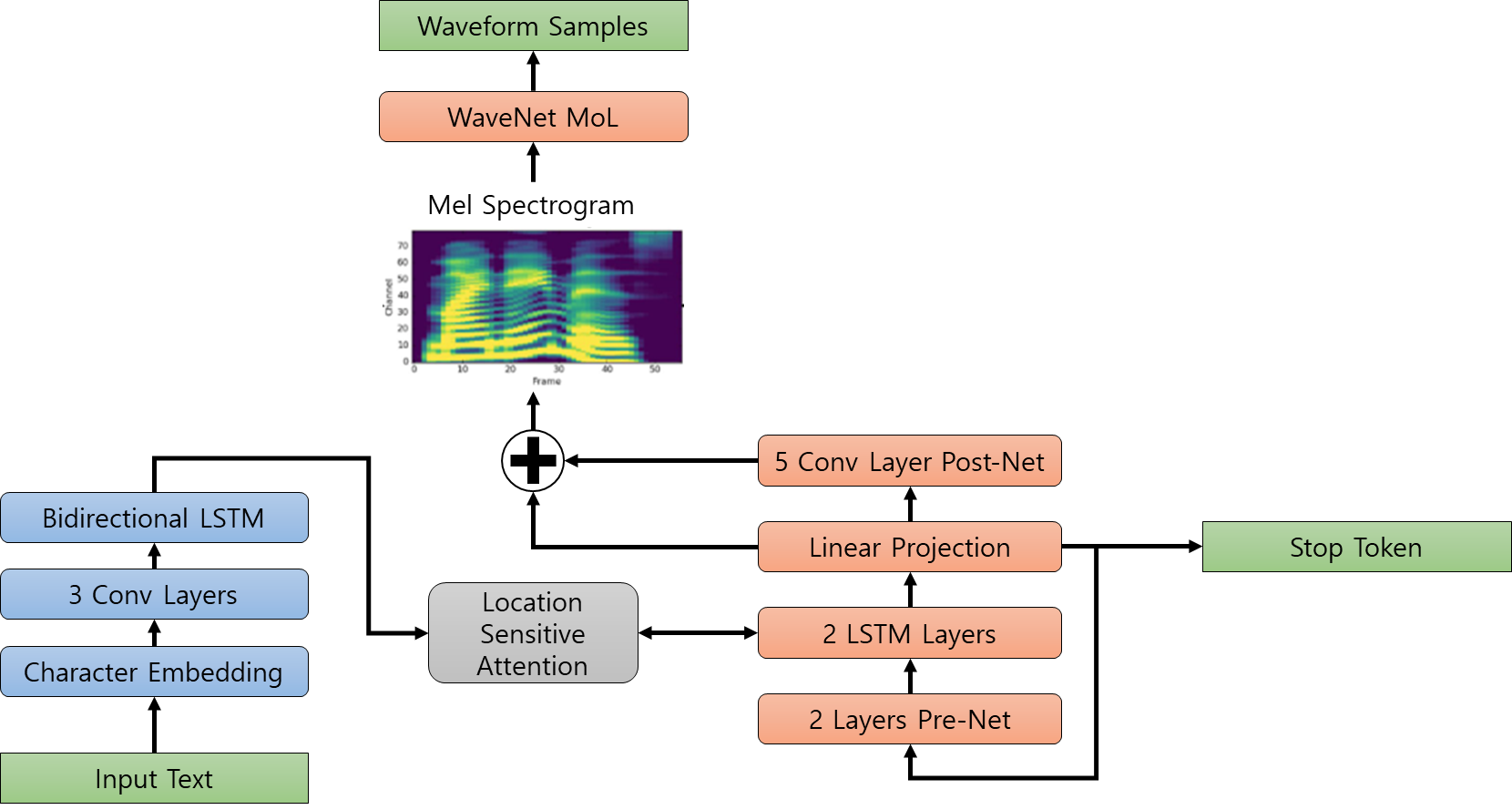
- 인코더(Incoder)
- i-vector 또는 x-vector 등과 같은 특징 추출기법으로 이루어진 Character Embedding 계층
- 3개의 Conv Layers(Convolutional Layer)
- 양방향 LSTM(Long-Short Term memory Layer)로 구성되어있다.
- 디코더(Decoder)
- 인코딩 된 입력 시퀀스에서 Mel-Spectrogram을 예측하는 자기 회귀 RNN(Autoregressive Recurrent Neural Network)을 포함한다.
- 어텐션(Attention)
- 디코더의 Attention 가중치를 계산하기 위해 내용기반의 Attention과 위치기반의 Attention을 혼합한 Location-Sensitive Attention 사용

Location Sensitive Attention 계산식
[논문] Shen, Jonathan, et al. "Natural tts synthesis by conditioning wavenet on mel spectrogram predictions." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
728x90