728x90
x-vector 클러스터링 기반의 Speaker Diarization
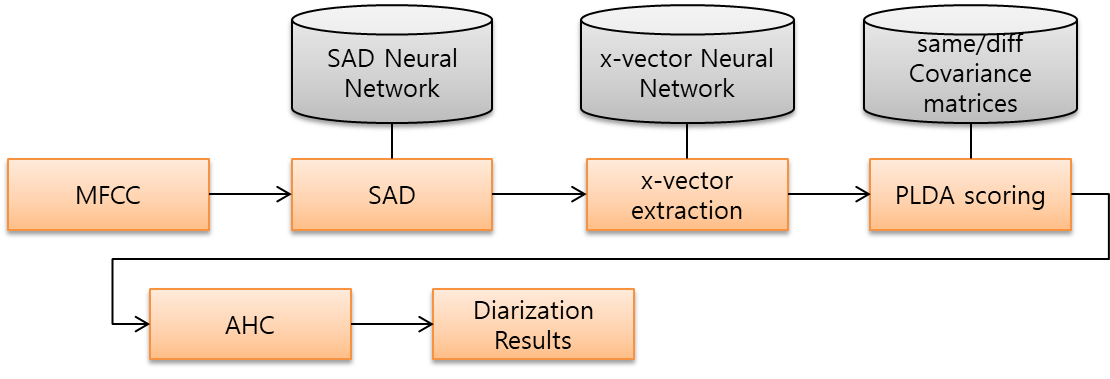
Speaker Diarization based on x-vector clustering - SAD(Speech Activity Detection) : 음성(Speech)과 비음성(Non-speech) 구간 검출 (VAD와 유사)
- x-vector extraction : x-vector 특징 추출
- PLDA scoring : 확률적 선형 판별 분석 점수 계산
- AHC(Agglomerative Hierarchical Clustering)
- 작은 단위로부터 클러스터링을 시작하여 모든 데이터를 묶을 때까지 반복하는 Bottom-Up 방식으로 클러스터링을 진행
- 가장 근접한 데이터끼리 클러스터링을 진행 -> 클러스터와 가장 근접한 데이터를 클러스터링 -> 하나의 클러스터링이 될때까지 반복 진행
- 참고 Recipe : kaldi/egs/libri_css/s5_mono [Link]
[참고 논문] L. Federico, et al. "Bayesian HMM clustering of x-vector sequences (VBx) in speaker diarization: theory, implementation and analysis on standard tasks." arXiv preprint arXiv:2012.14952(2020)
728x90
'Speech AI > 음성 인식' 카테고리의 다른 글
| [음성인식] x-vector (0) | 2021.12.02 |
|---|---|
| [KALDI] VoxCeleb Recipe 따라하기 (0) | 2021.12.01 |
| [음성인식] 화자 확인 평가방법 (EER, minDCF) (0) | 2021.11.30 |
| [음성인식] 화자분리(Speaker Diarization) (0) | 2021.11.22 |
| [음성인식] 음성인식의 개념 (0) | 2021.11.19 |