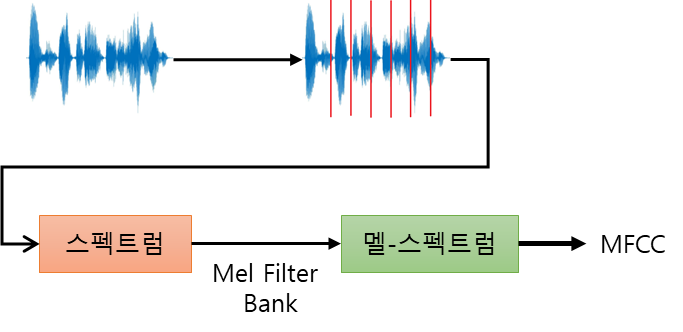
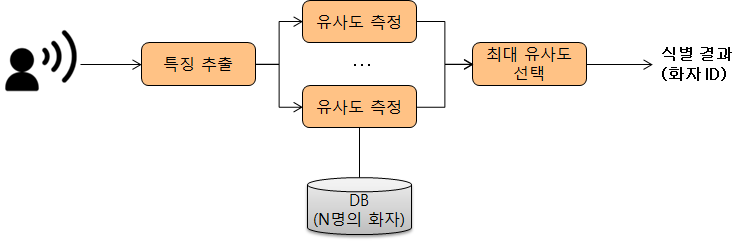
MFCC(Mel-Frequency Cepstral Coefficient) 음성 처리 또는 오디오 신호 처리 분야에서 널리 쓰이는 특징(Feature) 파라미터이다. MFCC는 여러 분야에서 활용이 된다. 예를 들어 음성 처리 분야에서는 화자 검증을 할 때 화자의 신원을 확인하는 방식으로 사용이 된다. 그리고 오디오 신호 처리 분야에서는 음악의 장르를 구별하는 방식으로 사용이 가능하다. MFCC를 기술적으로 설명하면 Mel-Spectrum(멜 스펙트럼) 에서 Cepstral(캡스트럼)분석을 통해 특징 값을 추출한다. 아래 그림은 FMCC의 추출 과정이다. 음성 신호를 작은 크기(20~40msec)의 프레임으로 쪼개어 고속 푸리에 변환(FFT, Fast Fourier Transform)을 적용해 스펙트럼을 ..